摘 要:商用密码算法的高性能实现是影响网络安全建设与密码泛在化应用的重要环节。聚焦SM2、SM3、SM4 算法,体系化、层次化研究不同商密算法的高性能软件实现优化技术,从理论分析、测试验证等维度对比分析优化技术并形成应用建议,以应用实践的方式介绍高性能商密算法的典型场景,为高质量商用密码发展提供支撑。
内容目录:
1 商用密码算法简介
2 商密算法性能优化技术研究
2.1 SM2 算法性能优化
2.2 SM3 算法性能优化
2.3 SM4 算法性能优化
3 商密算法性能优化分析评估
3.1 SM2 算法性能优化分析评估
3.2 SM3 算法性能优化分析评估
3.3 SM4 算法性能优化分析评估
3.4 评估分析总结
4 商密算法性能优化应用实践
4.1 面向政务云的高速率 SM2 签名服务应用
4.2 基于高性能商密算法的隐私计算应用
5 结 语
密码是网络空间安全的根本性核心技术。我国将密码分为核心密码、普通密码、商用密码。商用密码用于保护不属于国家秘密的信息,被广泛应用于政务、金融、能源、交通、水利、通信等行业领域以及大众消费场景,与关键信息基础设施安全、社会稳定以及经济发展等息息相关。
我国高度重视商用密码的发展与应用,先后提出了多项商用密码算法 ,并以标准牵引、顶层推广等方式,有效促进商用密码在各行业、各领域、各场景的深化应用。一直以来,高效率密码运算是密码技术及密码产品的核心。学术界、工业界均对商用密码进行性能优化研究与实践,提升核心竞争能力,保障高质量密码供给。
本文关注商用密码算法的高性能软件实现技术,以体系化技术分析的视角,深入研究 SM2、SM3 及 SM4 等算法的高性能实现方法,从理论分析与仿真评估的维度给出不同优化方法的对比分析结果,得出不同优化技术的应用建议,最后以应用实践的方式介绍高性能商密算法的典型场景,对高质量密码供给与应用能力建设有一定参考价值。
1
商用密码算法简介
我国大力发展商用密码技术与应用,已公开的商用密码算法包括 SM1、SM2、SM3、SM4、SM7、SM9 及 ZUC(祖冲之)算法。SM2、SM3、SM4 这3 项密码算法是 PKI 体系最常用的算法,也是使用最为广泛的商密算法,鉴于此,本文重点研究此3 种算法。
SM2、SM3、SM4 算法均由中国国家密码管理局发布,并先后成为密码行业标准、国家标准及国际标准 。SM2 算法是我国采用的公钥密码算法,其安全性基于椭圆曲线离散对数困难问题,算法主要包括数字签名、密钥交换协议和公钥加密算法3 个部分。在 PKI 体系中,基于 SM2 算法的数字签名技术在我国电子认证领域已广泛应用。SM3 算法是我国采用的密码杂凑函数标准,消息分组长度为512 位,摘要值长度为 256 位。SM3 算法广泛应用于密码协议、数字签名、消息鉴别、完整性认证等领域。SM4 算法是我国采用的分组密码算法,算法采用非平衡 Feistel 结构,加密算法和密钥扩展算法迭代轮数均为 32 轮,分组长度和密钥长度均为 128比特。SM4 算法主要用于数据的机密性保护,在音视频加密保护、云存储加密、数据库加密、安全通道保护、敏感信息保护等领域广泛使用。
2
商密算法性能优化技术研究
本节针对 SM2、SM3、SM4 算法特点,基于工业界、学术界已有成果,结合最新技术发展趋势,分层次、体系化地梳理研究商密算法的高性能软件实现技术。
2.1 SM2 算法性能优化
SM2 算法是基于椭圆曲线的公钥密码算法,算法依赖于椭圆曲线上的点运算,包括点加、倍点、点乘(标量乘)运算,以及有限域上大整数的算术运算,包括有限域上的加法、减法、乘法、乘法逆等。这些运算使得 SM2 具有层次结构,自上而下可以将其分为 4 层,如图 1 所示。在算法优化中首先关注椭圆曲线点运算,其次是有限域中大数运算,这些算法的计算量大、结构复杂,存在算法效率不高、资源消耗较多等问题,因此国内外众多学者对椭圆曲线算法、大整数基本运算进行了大量的研究。本节就 SM2 算法的主要优化方法进行了研究总结,总体而言优化方法可以分为椭圆曲线运算优化、大整数运算优化两大类。
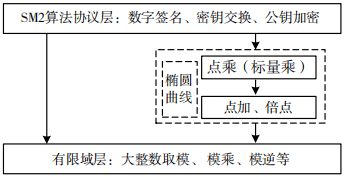
图 1 SM2 算法层次结构
2.1.1 不同坐标系中点加与倍点运算
椭圆曲线上点坐标的表示方法 主要用仿射坐标 (x,y) 和射影坐标 (x,y,z) 表示,这两种坐标可相互转换。射影坐标一般分为标准射影坐标、Jacobian加重射影坐标。
仿 射 坐 标 中 椭 圆 曲 线 的 表 示 方 程 公 式 为:







2.1.2 点乘运算
椭圆曲线点乘为 R=kP,其中 k 为整数,P 为椭圆曲线上的任意点。点乘运算通过点加与倍点运算构成,它是椭圆曲线最核心且非常耗时的运算,其计算速度从整体上决定了椭圆曲线密码体制的效率。目前点乘运算的研究方法很多,主要为 k 的表达形式与预处理方式。k 的表达形式是将 k 进行不同的表示后,在计算 k 的过程中融入点加与倍点运算得到点乘结果。预处理方式是 P 为固定值,将 P的倍点进行存储,然后通过查表计算当前倍点值。以下给出了有代表性的研究方法。
(1)二进制方法。二进制表示方法将 k 以二进制的形式展开为
(2)NAF 展 开 法。非 相 邻 型 表 示(Non Adjacent Form,NAF)是 k 的一种带符号表示方法,k 的 NAF 表示为


(3)窗口方法。窗口方法的思想是一次扫描w 位(w 为窗口宽度),使点 P 一次完成








(4)双基链方法。双基链算法是基于 Dimitrov提出的一种双基数系统,将整数 k 用两个不同的基表示,其最多在 O(logk/loglogk) 的时间复杂度内表示一个数。在双基链系统中,对任意整数k可表示为
2.1.3 素数域大整数运算
椭圆曲线上的点运算最终为有限域上的算术运算,有限域算术运算实现效率也影响着整数算法实现的效率。有限域上的运算包括加法、减法、乘法和模逆等基本运算,域上的加法、减法运算与代数运算方法基本相同,不同之处在于其运算结果需要求模,即约减。有限域上的约减、模乘、模逆等计算都非常复杂,耗时多,因此本节对这几种方法进行研究。
(1)约减。约减是有限域中的基本运算之一,针对约减的优化主要有 Barrett 约减、Montgomery约减、快速约减这 3 类方法。Barrett 约减是一种低成本的求商运算,估算出一个近似值


(2)模乘。本文称用于
(3)模逆。对于素数






2.2 SM3 算法性能优化
如图 2 所示,SM3 杂凑算法采用 M-D 结构的构造方式,对长度为

图 2 SM3 M-D 结构
文献 [13] 利用 Intel VTune Amplifier XE 分析了普通实现 SM3 算法的热点,压缩函数和消息拓展是最耗时的部分,其耗时分别占总耗时的 65.9% 和24.3%。因此,SM3 算法中的压缩函数和消息拓展是实现 SM3 算法性能优化的重要方法。此外,随着硬件技术的发展,X86、ARM 等主流硬件平台均推出了 SIMD 指令,可以在上述环节嵌套并行指令以进一步提升性能。
2.2.1 消息拓展和压缩函数优化
SM3 算法性能优化主要是从消息拓展和压缩函数两方面展开。消息拓展是将 512 比特的消息分组扩展到 132 个消息字。在优化实现中,将拓展的132 个消息字计算调整到压缩函数中执行,以减少数据加载和存储。压缩函数的优化实现可以通过调整结构和流程、常数计算等方面着手,可归纳为减少压缩函数循环移位导致的赋值运算次数;对压缩函数的中间变量生成流程进行优化,去除不必要的赋值,减少中间变量个数;利用预计算和存储常数,以进一步优化常数运算。
2.2.2 SIMD 并行指令优化
上述技术方案未考虑硬件指令加速的情况。事实上,SIMD 指令可以加速消息拓展的部分实现 ,图 3 较为清晰地展示出了如何利用 SIMD 优化 SM3。

图 3 SIMD 优化的 SM3
每一个










2.3 SM4 算法性能优化
SM4 是一个分组密码算法,分组长度和主密钥长度均为 128 bit。128 bit 主密钥经过密钥拓展算法拓展为 32 个 32 bit 轮子密钥,加 / 解密变换均为 32轮轮函数 F 的迭代。轮函数涉及比特操作以及合成置换 T。T 是由非线性变换 τ 和线性变换 L 构成。上述流程中最为耗时的部分是非线性变换 τ,其核心涉及 S 盒查表操作。目前针对 SM4 算法性能优化的方法也主要集中于 S 盒操作的优化,包括直接查表优化、SIMD 优化 、复合域 及比特切片等。
2.3.1 查表优化
查表优化实现是 SM4 算法优化实现方法中最早出现、最常见的方法,其核心思想是将密码算法轮函数中尽可能多的变换操作通过预计算制成表,即通常所说的“查大表”。
2.3.2 SIMD 并行指令优化
并行分为细粒度并行和粗粒度并行 2 种。由于 SM4 算法不适合使用细粒度并行,因此选取粗粒度并行策略实现 SM4。粗粒度是多组消息的并行处理,分组密码通常是在某种工作模式下加 / 解密大量数据,在特定的工作模式,如在电码本模式(Electronic Codebook Book,ECB)、 计 算 器 模式(Counter,CTR)、Galois 计 数 器 模 式(Galois/Counter Mode,GCM)、密码分组链接模式(Cipher Block Chaining,CBC)(解密方向)下,分组密码可并行处理多组消息。下述为 128 bit 寄存器下的SIMD 并行操作:
(1)查表指令:首先使用 1 ~ 4 个 128 bit 的向量寄存器构成查找表,其次使用另一个 128 bit 寄存器作为索引,将结果存入 128 bit 寄存器中。
(2)SM4 并 行 查 表:SM4 的 S 盒 一 共 有256×8 bit,即需要消耗 16 个向量寄存器存储查找表,每次查表最多能使用 4 个向量寄存器作为查找表,进行 4 轮的查表。
(3)SM4 数据加载:在一轮 SM4 迭代过程中,需要查表的数据为 32 bit,为了尽可能利用好 128bit 的向量寄存器,将 4 组消息的 32 bit 集中于同一个向量寄存器中。
2.3.3 复合域及比特切片
与传统基于查找表法的方式相比,该方法采用代数运算的方式,计算较为简单。S 盒的运算由两部分构成:线性的仿射变换和非线性的有限域求逆。仿射变换容易实现,因此主要计算难度在于


3
商密算法性能优化分析评估
本节对前述商密算法优化技术进行理论分析与仿真评估,给出不同优化方法的对比分析结果,最后从实践的角度给出应用建议。
3.1 SM2 算法性能优化分析评估
3.1.1 点加与倍点运算
点加与倍点是椭圆曲线的计算基础,不同坐标系下其计算方法不同导致计算效率也不同。仿射坐标计算点运算需求模逆,计算复杂度高,耗时多,效率低,因此在实际工程实现中通常不考虑该方法。相比来说,Jacobian 加重射影坐标的运算效率最高,因此在工程实现中通常采用 Jacobian 加重射影坐标进行点运算。为了方便使用,工程实现对外点的表示使用仿射坐标,内部计算时存在 Jacobian 加重射影坐标与仿射坐标的相互转换。
3.1.2 点乘运算
本文研究了点乘运算二进制方法、NAF 展开法、窗口方法以及双基链方法。二进制方法中非零符号的汉明权重未做优化,开销较大,现已很少使用。NAF 展开法的性能通常会低于窗口方法。双基链方法使用贪心算法,汉明权重很难预估,运行速度不确定因素较大,工程应用较少考虑。本节将重点对比分析窗口方法中的滑动窗口算法 w-NAF、booth编码与固定窗口结合方法。
SM2 算法素数域长为 256 位,在 256 位数据长度中对不同宽度下基于 w-NAF 与基于 booth 编码的两种点乘算法进行性能分析。本节针对两种不同点的形式(固定点乘与非固定点乘)分别进行了比较分析,结果见表 1,其中,PA 和 PD 分别代表一次点加和倍点运算,M 代表一次乘法运算。
表 1 w-NAF 与 booth 编码的点乘性能分析

对固定点采用预计算存储方式实现点乘运算时,随着宽度增加,两种方法的计算量都在减少、存储量增加。宽度相同时基于 w-NAF 方法的计算开销比基于 booth 方法的计算开销高很多,存储开销少很多。为提高计算效率,基于 booth 编码的方法效率会更高。选择宽度时,如不考虑存储开销则宽度越大效率越高,但实际应用中,存储资源是有限的,应综合考虑计算与存储开销,因此选择宽度为 7 的基于 booth 编码的算法较为适用。
当点不固定时,两种算法在宽度为 5 处计算开销都最低。当两种计算开销最低时,基于 w-NAF的点乘性能稍优于基于 booth 编码的点乘性能。SM2 算法中两种点乘方式的使用频率基本相等,综合分析 SM2 算法采用基于 booth 编码方式实现的效率会更高,并且安全性更好。
3.1.3 素数域大整数运算
在约减运算方面,Barrett 约减及 Montgomery 约减性能大致相当。快速约减算法不需要除法,性能是最好的,推荐使用。在模乘运算方面,由于Montgomery 模乘算法通过移位避开了除法运算,其性能优于 Barrett 约减的模乘算法及 KOA 快速乘法,推荐使用。同时,Montgomery 模乘算法底层使用Montgomery 约减算法,因此在工业应用中可配合使用。在模逆运算方面,重点分析比较基于二进制的欧几里得求逆算法和 Lehmer 扩展欧几里得求逆算法。本文在 Intel(R) Core(TM) i5-7500 平台上,用 32字节的数据测试了两种求逆方法的性能,测试结果如表 2 所示。测试结果表明 Lehmer 欧几里得算法的性能是二进制欧几里得算法的 4 倍左右。推荐采用 Lehmer 欧几里得算法。
表 2 两种模逆算法性能测试结果

3.2 SM3 算法性能优化分析评估
本文对 2.2 节提出的两项 SM3 性能优化技术方案进行测试验证。方案 1 为 C 语言实现,采用消息拓展和压缩函数。方案 2 为汇编实现,采用消息拓展压缩函数以及 SIMD 指令。对比基线为原始未优化算法。经试验测得,方法 1 和方法 2 加速效果相当,相比于原始算法性能均能提高 1 倍左右。不同之处在于方案 1 的性能与平台差异较小,方案 2 的性能与平台关系较大,若平台对汇编指令支持不够友好,则可以用于并行加速的部分甚少,加上汇编语言会增加代码的复杂度,整体性能会有所下滑。在具体项目应用中,建议在兼容性较好的硬件平台采用方案 2,在硬件环境比较特殊的场景下采用方案 1。
3.3 SM4 算法性能优化分析评估
本文 2.3 节研究了 3 项 SM4 性能优化技术方案。本节针对查表优化(方案 1)、SIMD 并行指令优化(方案 2)两项技术方案进行了对比测试,对比基线为原始未优化算法。采用 SM4 ECB 模式。经试验测得,方案 1 相比于基线方案性能提高至 2.7 倍,方案 2相比于基线方案性能提高至 5 倍。整体来说,方案2 的性能优于方案 1,但方案 2 与平台相关,加速效果不尽相同,方案 1 跨平台,可以广泛使用。此外,比特切片及复合域等创新技术往往是在 SIMD 基础上进行的再度优化,性能高于方案 1 和方案 2,但该方法也存在硬件平台的差异,推荐在硬件支持的情况下使用。
3.4 评估分析总结
基于上述分析,总结商密算法性能优化方法的性能情况、应用场景并给出推荐指数建议,见表 3。针对 SM2、SM3、SM4 算法,本文总结的相关方法大部分可以配合使用,以达到性能叠加的效果。同时部分优化技术与硬件平台强关联,比如 CPU 指令集是否支持、CPU 位宽情况、硬件存储资源是否受限等,在具体应用时,应结合硬件资源情况,进行方法的组合和筛选,在满足实际需求的同时最大限度地提升性能。
4
商密算法性能优化应用实践
随着“等保”“密评”“国密改造”等工作的推进,商用密码应用呈现泛在化发展趋势,越来越多的信息系统纷纷采用商用密码技术进行安全保护。本文选取云计算、隐私计算两大创新场景,以新技术融合应用的视角,介绍高性能商密算法应用实践。
4.1 面向政务云的高速率 SM2 签名服务应用
政务云承载了大量的政务数据与应用,具备大规模集中计算、高效率业务保障、统一身份认证等需求。在政务云中构建密码资源池,采用云签名验签服务器提供高效率的 SM2 签名服务,同时考虑系统的可扩展性,在密码资源池中基于虚拟化服务器,部署高性能 SM2 软算法,配套提供 SM2 软算法签名服务,通过软、硬两套方案协同,针对不同等级用户、不同应用对象按需提供密码运算功能,确保服务的可用性。相关应用场景见图 4。
表 3 商密算法性能优化评估总结


图 4 面向政务云的高速率 SM2 签名服务场景
4.2 基于高性能商密算法的隐私计算应用
隐私计算是数据要素化发展的关键技术,密码是其安全基石。隐私计算包含大量的对称加密、消息杂凑、非对称运算等密码算法。可基于高性能商密算法,打造安全、合规的隐私计算协议。图 5 为融合高性能商密算法的隐私计算应用场景,系统采用三方外包计算的模式,计算方在执行隐私计算协议时,将优化后的 SM4 算法应用于混淆电路场景中,优化后的 SM2 椭圆曲线算法应用于 PSI 场景中,优化后的 SM3 消息杂凑算法应用于特征工程等算法协议中,系统在实现密码算法的国密改造的同时,也极大程度地提升了性能,促进新技术的融合应用发展。

图 5 基于高性能商密算法的隐私计算应用场景
5
结 语
本文立足于 SM2、SM3、SM4 算法,分层次、成体系地梳理研究了商密软算法的高性能优化实现方法,给出了不同优化技术的理论分析与仿真评估结果,得出了相关优化技术的应用建议,并以应用实践的方式探讨了高性能商密算法的应用场景,为高质量密码能力建设提供了参考路径。下一步,将深入应用场景及平台环境,细化细分领域的算法优化技术方案,以进一步支撑高性能商密算法应用落地。















![拜小白opencvvs2017[拜小白工厂]](/upload/images/36933963)


