服务网格可观测性之平台化监控报警
 #################################### Unified Alerting ####################
[unified_alerting]
#开启统一报警模块
enabled = true
#################################### Unified Alerting ####################
[unified_alerting]
#开启统一报警模块
enabled = true
配置"统一警报模块"高可用
#################################### Unified Alerting ####################
[unified_alerting]
#开启统一报警模块
enabled = true
#监听地址/主机名和端口,用于接收其他Grafana实例的统一警报消息。
ha_listen_address = "${POD_IP}:9094"
#监听地址/主机名和端口,用于接收其他Grafana实例的统一警报消息。
ha_advertise_address = "${POD_IP}:9094"
#以“主机:端口”的格式列出初始实例(逗号分隔),这些实例将组成HA集群。配置此设置将启用警报的高可用模式。
#注: 此pod申请固定IP,也可以将grafna部署为statefulset模式。
ha_peers = 10.23.2.32:9094,10.23.2.33:9094,10.23.2.34:9094
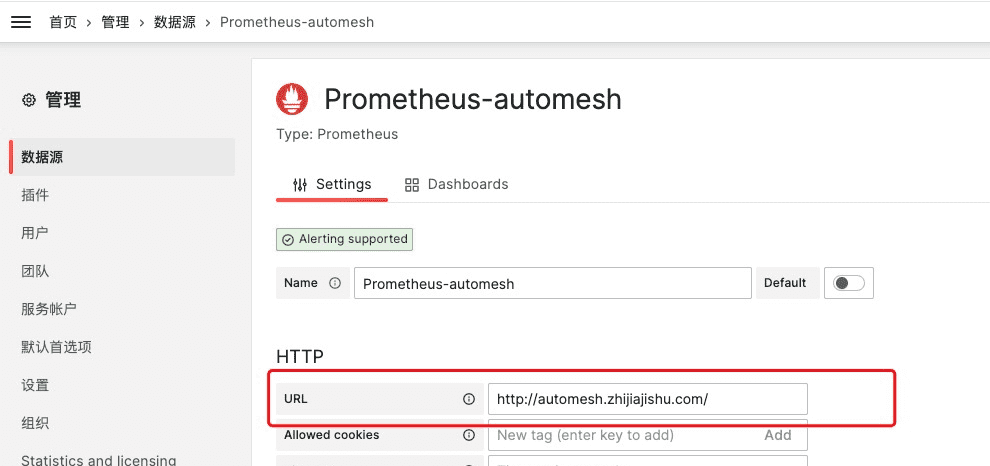
3.2案例说明
下面是此案例的数据流图:
 http_server_duration_bucket{http_method="GET", http_route="/v1/app/getVehicleList", http_status_code="200", instance="10.29.2.9:9464", le="0.0", service="vehicle_service"} 0.0
http_server_duration_bucket{http_method="GET", http_route="/v1/app/getVehicleList", http_status_code="200", instance="10.29.2.9:9464", le="5.0", service="vehicle_service"} 102356.0
http_server_duration_bucket{http_method="GET", http_route="/v1/app/getVehicleList", http_status_code="200", instance="10.29.2.9:9464", le="10.0", service="vehicle_service"} 136099.0
http_server_duration_bucket{http_method="GET", http_route="/v1/app/getVehicleList", http_status_code="200", instance="10.29.2.9:9464", le="25.0", service="vehicle_service"} 163764.0
http_server_duration_bucket{http_method="GET", http_route="/v1/app/getVehicleList", http_status_code="200", instance="10.29.2.9:9464", le="50.0", service="vehicle_service"} 175603.0
http_server_duration_bucket{http_method="GET", http_route="/v1/app/getVehicleList", http_status_code="200", instance="10.29.2.9:9464", le="75.0", service="vehicle_service"} 179163.0
http_server_duration_bucket{http_method="GET", http_route="/v1/app/getVehicleList", http_status_code="200", instance="10.29.2.9:9464", le="100.0", service="vehicle_service"} 180891.0
http_server_duration_bucket{http_method="GET", http_route="/v1/app/getVehicleList", http_status_code="200", instance="10.29.2.9:9464", le="250.0", service="vehicle_service"} 182806.0
http_server_duration_bucket{http_method="GET", http_route="/v1/app/getVehicleList", http_status_code="200", instance="10.29.2.9:9464", le="0.0", service="vehicle_service"} 0.0
http_server_duration_bucket{http_method="GET", http_route="/v1/app/getVehicleList", http_status_code="200", instance="10.29.2.9:9464", le="5.0", service="vehicle_service"} 102356.0
http_server_duration_bucket{http_method="GET", http_route="/v1/app/getVehicleList", http_status_code="200", instance="10.29.2.9:9464", le="10.0", service="vehicle_service"} 136099.0
http_server_duration_bucket{http_method="GET", http_route="/v1/app/getVehicleList", http_status_code="200", instance="10.29.2.9:9464", le="25.0", service="vehicle_service"} 163764.0
http_server_duration_bucket{http_method="GET", http_route="/v1/app/getVehicleList", http_status_code="200", instance="10.29.2.9:9464", le="50.0", service="vehicle_service"} 175603.0
http_server_duration_bucket{http_method="GET", http_route="/v1/app/getVehicleList", http_status_code="200", instance="10.29.2.9:9464", le="75.0", service="vehicle_service"} 179163.0
http_server_duration_bucket{http_method="GET", http_route="/v1/app/getVehicleList", http_status_code="200", instance="10.29.2.9:9464", le="100.0", service="vehicle_service"} 180891.0
http_server_duration_bucket{http_method="GET", http_route="/v1/app/getVehicleList", http_status_code="200", instance="10.29.2.9:9464", le="250.0", service="vehicle_service"} 182806.0
数据说明:此Metrics数据描述了HTTP 服务的响应时间分布数据,通过这些 metrics 数据可以得到该 HTTP 接口在不同响应时间区间的请求数量,以及每个区间的响应时间度量值。例如,在此数据中,le=5.0 的 bucket 中有 102356 次请求,对应的响应时间在 0 到 5 秒之间,le=250.0 的 bucket 中有 182806 次请求,对应的响应时间在 0 到 250 秒之间。